部署yolo模型到jetson
pt转engine
安装python库
cpu即可直接运行,不一定非得用nvidia显卡
shell
pip install onnxslim
pip install onnxscript
pip install ultralytics onnx onnxruntime将pt模型,转换为onnx
修改对应版本的导出代码,这里使用的是yolo11,修改utils/export_yolo11.py,修改原因为
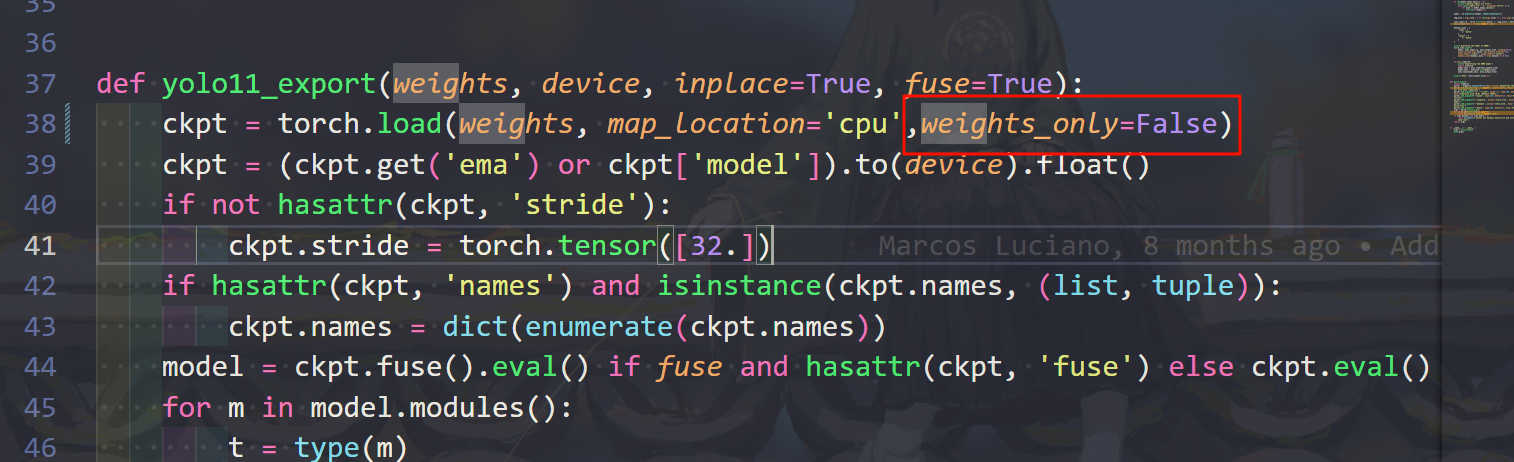
和
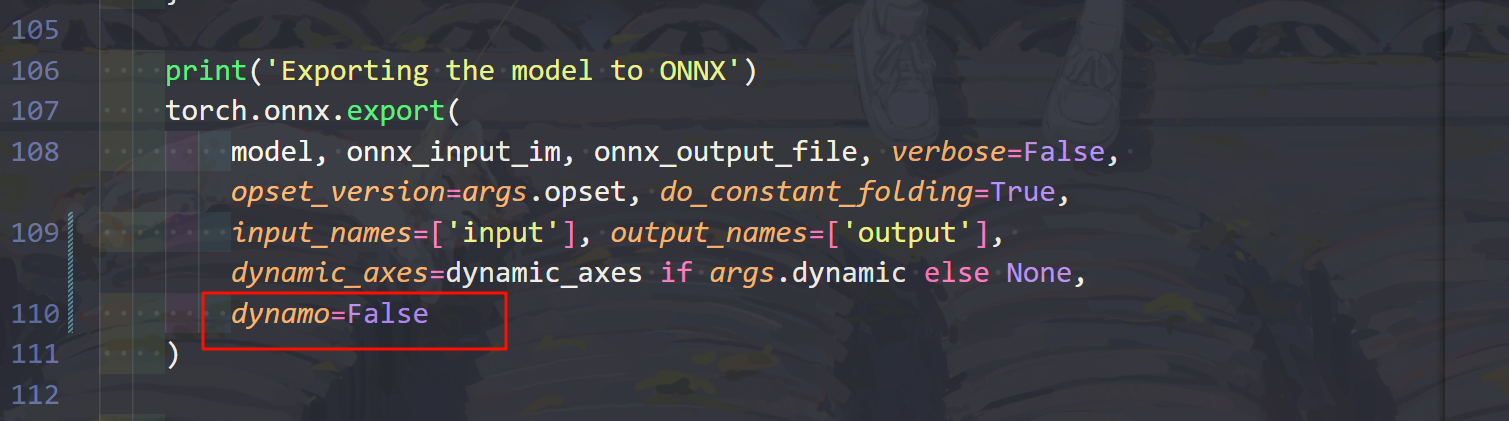
然后导出简化版onnx
在D:\work\jetson\DeepStream-Yolo\utils下执行
shell
python export_yolo11.py -w D:\codes\afnhai\rock\best.pt --dynamic --simplify -s 640 640执行完毕后会在D:\codes\afnhai\rock\best.pt的同级目录下产生一个best.pt.onnx文件
将onnx转换为engine文件并部署
onnx转engine
将best.pt.onnx上传到jetson中,这里上传到了/home/nvidia/codes/stone/model下
/usr/src/tensorrt/bin/trtexec是deepstream sdk中带的
在/home/nvidia/codes/stone/model下执行
shell
sudo /usr/src/tensorrt/bin/trtexec --onnx=best.pt.onnx --saveEngine=rock_b1_640_fp16.engine --optShapes=input:1x3x640x640 --fp16 --memPoolSize=workspace:4096M --verbose执行完毕后会在同级目录下产生rock_b1_640_fp16.engine文件
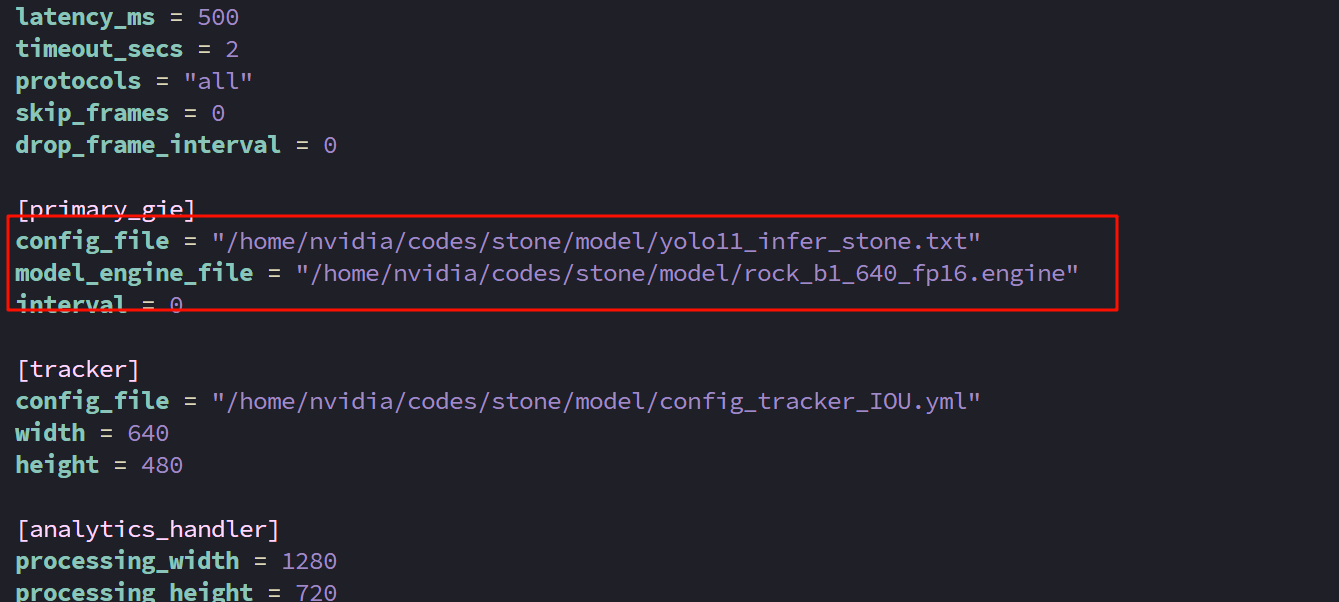
修改模型配置文件
从deepstream sdk中拷贝出config_tracker_IOU.yml文件,这里/home/nvidia/codes/stone/model已经有了
在~/codes/stone/model下新建一个yolo11_infer_stone.txt文件
shell
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
model-color-format=0
onnx-file=best.pt.onnx
model-engine-file=rock_b1_640_fp16.engine
#int8-calib-file=calib.table
labelfile-path=labels.txt
batch-size=1
network-mode=2
num-detected-classes=1
interval=0
gie-unique-id=1
process-mode=1
network-type=0
cluster-mode=2
maintain-aspect-ratio=1
symmetric-padding=1
#workspace-size=2000
parse-bbox-func-name=NvDsInferParseYolo
#parse-bbox-func-name=NvDsInferParseYoloCuda
custom-lib-path=nvdsinfer_custom_impl_Yolo/libnvdsinfer_custom_impl_Yolo.so
engine-create-func-name=NvDsInferYoloCudaEngineGet
[class-attrs-all]
nms-iou-threshold=0.45
pre-cluster-threshold=0.25
topk=300修改代码配置文件
修改项目根目录~/codes/stone下的config.toml文件
将配置文件和模型写为刚才产生的即可